


ABSTRACT
In this article, Giulio Corradi at AMD looks at the challenges of predictive maintenance and how it has changed in recent years, including how data and analytics requirements and capabilities can be orchestrated. Looking at potential architectures, the computing power required could take advantage of new adaptive computing devices like Adaptive Compute Acceleration Platforms (ACAPs), for managing the sheer amount of data and providing the necessary quality of service.
Introduction
Historically in a full-scale production setting, one of the best company assets was the experience of machine operators, as they had the ability to predict when maintenance was required. Plant managers reported about any unusual behaviour such as a clatter or clank in the machinery, prompting a check-up by the maintenance crew.
Today, the level of automation greatly reduces the operator’s ability to detect imminent failure and most of the maintenance is scheduled instead of predicted, or in some cases not noticed or ignored, leading to unnecessary plant downtime.
However, the recent worldwide COVID-19 pandemic has forced more unattended or remotely attended machinery operations, with minimum on-site operation and reduced maintenance crews. Thus, for plant managers, improving the ability for machinery to automatically detect and diagnose itself to predict faults, is now a strategic advantage.
Methodologies like Prognostic and Health Management (PHM), and initiatives like Predictive Maintenance 4.0 (PdM4.0), have existed for several years, but have now moved from the plant manager’s watch list into the priority list.
The target is for the optimal and timely maintenance actions for both automated and remotely based human-in-the-loop decision making.
PHM aims to collect and analyse data to provide a real-time status of the equipment’s health for estimating its Remaining Useful Lifetime (RUL), with algorithms that detect anomalies and diagnose imminent faults. The associated financial benefits include extending the equipment’s lifetime and reducing operational costs.
PdM4.0, as part of the Industry 4.0 and Industrial IoT (IIoT) initiatives, aims to provide more equipment autonomy, instrumenting it with more sensors for data collection, using digital signal processing, machine learning, and deep learning as tools for predicting failures and triggering maintenance activities.
Standards have been developed with vocabulary, presentation, and guidelines like IEEE 1451, 1232, the ISO series 13372, 13373, 13374, 13380, 13381 to provide common ground to Maintenance 4.0.
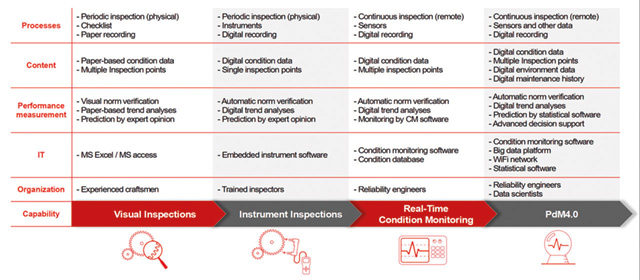
Figure 1 provides the path from the scheduled maintenance to PdM4.0, where it is apparent that the level of sophistication increases as you approach PdM4.0.
Challenges
However, while PHM and PdM4.0 have clear intentions and provide general recommendations, their practical implementation is not fully realized and require skillsets that are not readily available to plant or maintenance managers. To fully take advantage of PHM and PdM4.0 you must consider the following questions:
• First, when establishing the business case for the predictive maintenance implementation, the focus should be on the specific problems that minimise risk. Triggering the question: what are the critical assets that are likely to fail?
• Second, many plants still have machinery built with limited connectivity, thus the data collection isn’t readily available. Triggering the question: how do we instrument the machinery with more sensors capable to connect to Information Technology (IT) without compromising its reliability, safety, and security?
• Third, when the data and communication has been collected, the next challenge is how it is used. Triggering the question: how should the data be grouped to detect, predict and minimise the occurrence of failures?
Most of the time there is no obvious answer and the initial simplest idea is collecting all the data the plant and machinery produce, move this data to an on-premise data center in the cloud, and try to figure out some information using data analytics. That is also considered batch data.
Figure 2 shows the data funnel to the cloud and the different data sources that contribute to form the information for the predictive maintenance.
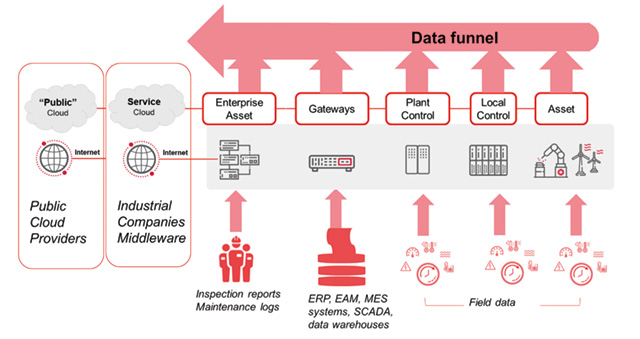
Not all plant and machinery data is created equal. There is unstructured data such as inspection reports, maintenance logs, raw material and batch organization, associated with the data available for predictive maintenance. There is structured data coming
from the enterprise automation technologies like ERM, EAM, and MES, providing another source of information to qualify the machinery conditions, workload and usage. This is also batch data.
The most unstructured information comes from the sensors connected to edge equipment, as the data stream is produced often at millisecond rhythm and in large volume.
PdM4.0 recommend an analytical framework as Figure 3.
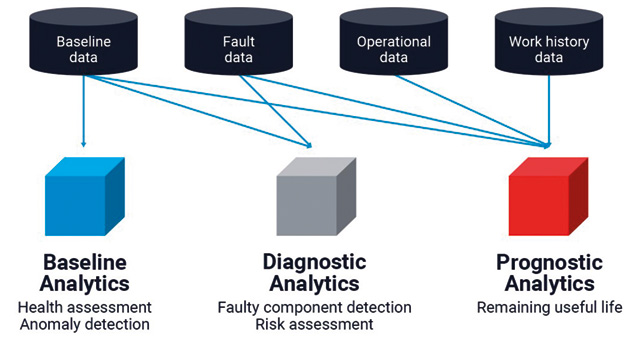
Baseline analytics detect irregular behaviour of the asset within milliseconds of the actual event. The data used to perform these analytics is usually local to the asset under consideration and relies on data acquired from the asset when it was working normally.
Diagnostic analytics that identify the root cause of the anomaly, such as a failing bearing in a motor, require previous knowledge of fault states. Diagnostics results can be returned in the order of minutes.
Prognostic analytics that tell you the remaining useful life of a bearing can take in the order of hours to return a result and requires access to multiple types of data, from multiple sources to make the prediction.
Implementation Architectures
Structured and unstructured data, batch and stream data, speed and volume are part of the larger analytics framework for the Industry 4.0 initiative, and predictive maintenance piggybacks on such framework. Two main architectures are emerging:
• Lambda Architecture
• Kappa Architecture
Lambda Architecture
Lambda Architecture is a deployment model for data processing to combine a traditional batch pipeline with a fast-real-time stream pipeline, for data access providing data-driven and event-driven in the face of massive volumes of rapidly generated data.
Figure 4 shows the Lambda architecture. Apache Kafka is often a framework used for implementing the Data Source. It is a distributed data store optimized for ingesting and processing streaming data in real-time, sequentially and incrementally. It acts as an intermediary store that can hold data and serve both the batch layer and the speed layer of the Lambda Architecture.
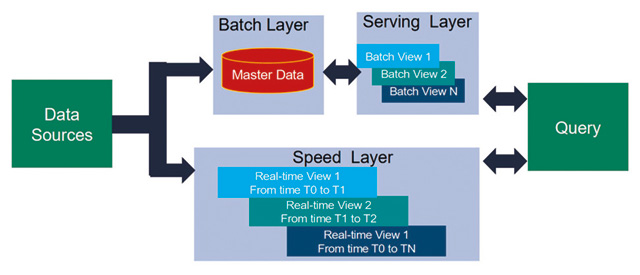
The Batch Layer is often implemented using a technology like Apache Hadoop for ingesting the data as well as storing the data in a cost-effective way. The data is treated as immutable and append-only to ensure a trusted historical record of all incoming data.
The Serving Layer incrementally indexes the latest batch views to allow queries by end users and processing is done in an extremely parallelized way, to minimize the time to index the data set.
The Speed Layer complements the serving layer by indexing the most recently added data that has not yet been fully indexed by the serving layer. In general, field gateways are targeted for this role being the closest to the streamed field data.
They ingest messages, filter data, provide identity mapping, log messages and provide linkage to cloud or on-premises gateways. It is not advantageous moving data upstream if the gateway can also perform local analytics and machine learning, and this functionality needs to consider CPU and memory sizing implications when sizing the field gateway platforms.
The Query Layer is what the data scientists, plant experts, and managers require to query on all data, including the most recently added data, to provide a near real-time analytics system.

better connected at a rapid pace
Kappa Architecture
Many organizations may have both batch and real-time and with very stringent end-to- end latency requirements, where complex transformations including data quality techniques can be applied in the streaming layer. Thus, Kappa architecture is a streaming first architecture deployment pattern.
Apache Kafka is used to ingest data and funnel it into stream processing engines like Apache Spark, Apache Flink, and others, to transform and publish the enriched data back to the serving layer for reporting, and dashboarding.
Hardware requirements for the edge equipment for PdM4.0
To deploy Lambda or Kappa architecture, the equipment and edge gateways that are embedded systems require enough computing performance and sufficient memory.
As an example lets focus on Apache Kafka, that can be deployed in such embedded system to support Lambda and Kappa architectures. Its deployment can be in different configurations, including bare metal, virtual machines (VM), containers, etc.
The minimum hardware requirement for running Apache Kafka with a very small footprint is a single-core processor and a few 100MBs of RAM. However, such small-scale implementation is not enough to provide the right quality of service for Lambda and Kappa architectures.
To be specific, in the Apache Kafka system concept the stream of messages is divided into particular categories called topics. These messages are published to specific topics using dedicated processes called producers.
The published messages are then stored in the set of servers called brokers. Fundamentally the Kafka broker expects the client producer (the field equipment) that will put messages into the system, the client consumer (the edge equipment) that will pull them out, and administrative client tools (in the field equipment and edge equipment) that allow creating topics, deleting topics, and setting up security settings.
Just those initial considerations for the broker, producer, consumer and administrative tools give a hint about the diverse needs.
For the producer, if we add the networking piece, and the data collection the computing performance and memory footprint can be a serious business for an embedded system. Thus, these are the characteristics of such embedded computing systems for providing the right amount of quality of service:
• Heterogeneous intensive I/O acquisition and processing;
• Capability to execute digital signal processing, to filter, extract spectral components, and reduce redundant data;
• Capability to run VM and containers;
• Capability to execute machine learning and deep learning inference in real-time; and
• Capability to support networking for operational data as well as for information technology.
You can find some of the above capabilities in system on chip (SoC), CPU or GPUs, but some fall short in I/O, others fall short in machine learning and digital signal processing, and some do not have adequate networking capabilities.
Among all such technologies though another category is emerging. Adaptive compute acceleration platforms (ACAPs), embed all the above capabilities including vector processing for machine learning and deep learning inference, scalar CPUs for running the frameworks, tightly coupled to programmable logic (PL) for real-time data acquisition and the I/O intensive processing.
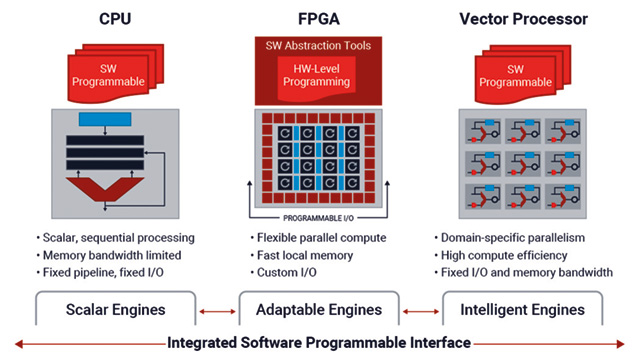
These are all tied together with a high bandwidth network-on-chip (NoC), which provides memory-mapped access to all three processing element types, and memory access to the acquired and processed data. ACAP then provides the resources needed to implement the baseline, and diagnostic analytic close to the data sources with capability to integrate the stream processing frameworks like Apake Kafka and the other clustering system.
Conclusion
Predictive Maintenance is a challenging endeavour and we described how data and analytics requirements and capabilities could be orchestrated.
This paper cannot cover all the details of the architecture, but the Lambda and Kappa architectures have been introduced to show a path to implementation describing how the speed and batch layer components works.
The computing power required at the edge could take advantage of new adaptive computing devices like the Xilinx ACAPs for managing the sheer amount of data and providing the necessary quality of service at the edge embedded level.
www.xilinx.com I christelle.moraga@amd.com I T: +44 (0)1223 518040

Dr. Ing. Giulio Corradi,
Principal Architect,
Industrial, Vision, Healthcare & Sciences, Adaptive and Embedded Computing Group, AMD